Workflows have been around software development for many decades. With its peak popularity around the SOA (service oriented architecture) times. Although it was always positioned as something on top, something superior. In fact, it led to smaller adoption as it became quite complex to build solutions on centralized workflow platforms.
Currently workflows are starting to be more and more popular again, though their main use case is around service orchestration. In my opinion, this is the biggest misconception around workflows - they are actually way more than just service orchestration.
What are workflows good at then?
Workflows serve very well in following use cases
business entity life cycle - a common use case in various enterprises or domains is to build systems that are responsible for an end to end life cycle of the business entity, e.g. parts in the automotive industry. Parts have well defined life cycle that goes through number of phases
event streams - execute business logic on top of the event stream. More and more common are IoT based use cases where workflows can run very close to the sensors without the need to push data to some cloud offerings for processing
batch processing - workflows are perfect fit for defining batch processors that are usually triggered by time events (run every night at 10pm) or by incoming message
human centric systems - workflows come with out of the box features that allow to model and implement advanced interactions with human actors such as reassignment, notifications, escalations and more
Kubernetes operators - operator pattern in Kubernetes is an excellent example where workflows have a natural place, operator logic is a constantly repeating the set of steps to reach the desired state of the resource, workflows can easily define the steps and then repeat consistently for each resource deployed to Kubernetes cluster
The other aspect of a bit misleading approach to workflows is that they are usually outside of the service or system. While this makes sense for service orchestration use cases, it does not bring much value when it comes to above mentioned scenarios. Instead, workflows could play an essential role in the service or system being built. Let’s explore what this could look like and how it corresponds to the cloud.
With that, let’s introduce three new concepts around workflows
workflow as a service
workflow as a function
workflow as a function flow
Workflow as a service
Workflow as a service aims at using workflows to be the base for creating service on top of it. This means that developers use workflows as a sort of programming language, yet another one in their tool box to avoid the need of developing the boilerplate code. Let’s break this down a little bit
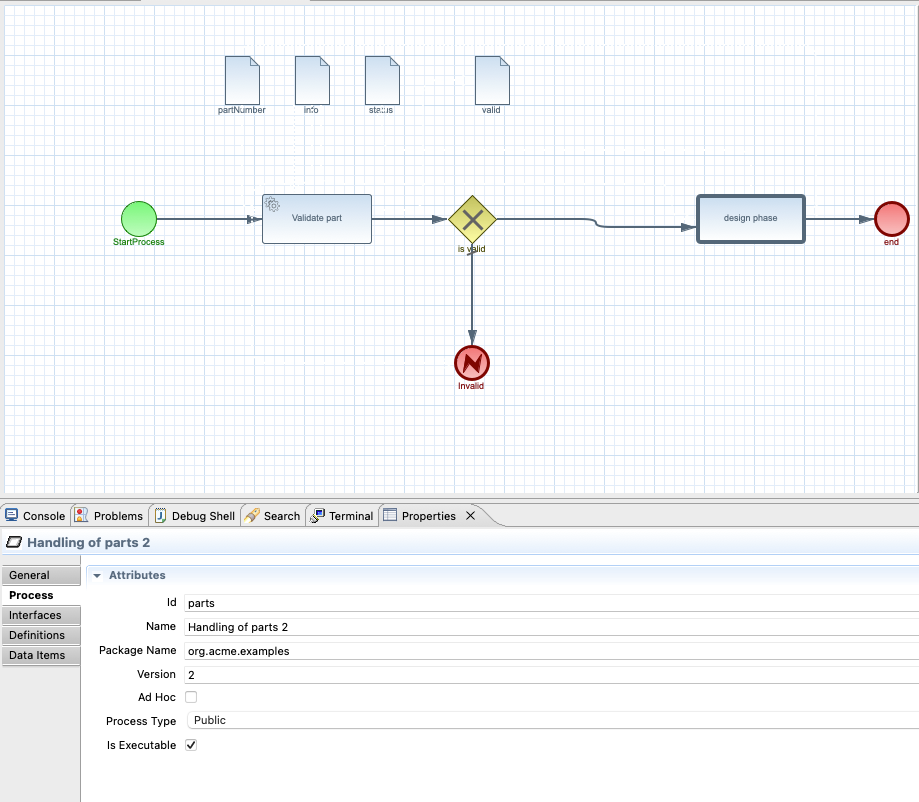
In the above workflow definition we can find few important aspects
set of activities that tells what will actually happen
data model (partNumber, info, status and valid) that represents a complete set of information associated with given resource
metadata of the workflow like id, name, version, etc
All of that is considered source information to build up a service from it. Essentially, workflow definition represents CRUD (create, read, update, delete) service interface. The data model represents the resource behind the service interface - it’s the entity that the CRUD operations are managing. Set of activities extends the CRUD service interface with additional capabilities to allow consumers of the service a richer interaction model.
Workflow as a service concept aims at using workflow definition as input and transforming it to a fully functional service interface with complete business logic implementation instead of just having a set of stubs generated. Main idea behind it is to allow developers to focus on what is important - the business logic that is specific to the domain they work in rather than developing things that can be easily derived from the business model - CRUD service interface.
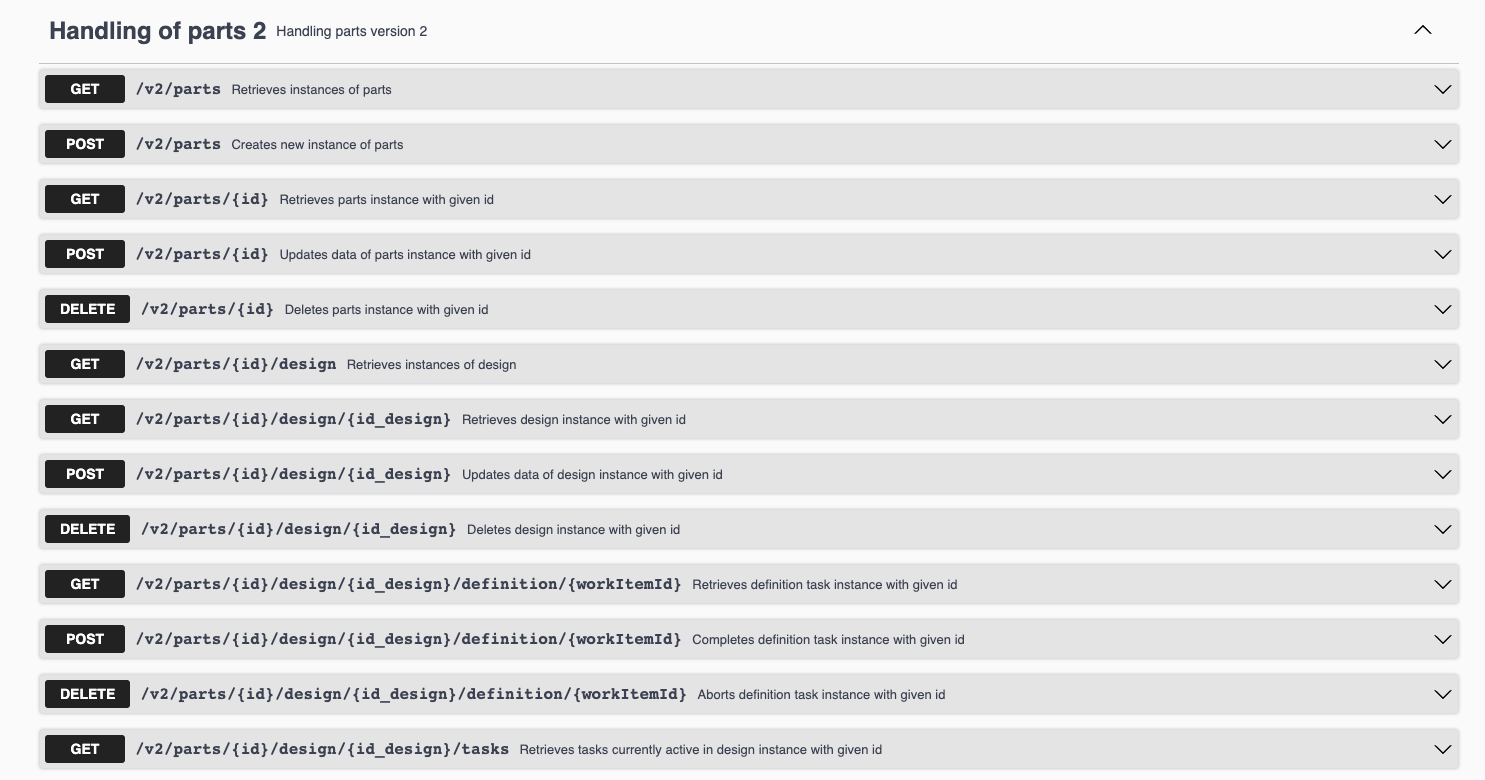
Workflow as a function
Workflow as a function aims at taking more advantage of the various cloud offerings to offload developers from taking care of infrastructure. Cloud functions become quite popular where the most famous is AWS Lambda, but certainly it is not the only one. Other ones that are popular are Azure Functions and Google Cloud Functions but there are others that are starting to pop out as well.
Workflows can be used to model a business logic that will be then deployed as a function to one of the cloud offerings. What is important is that the workflow acts like an abstraction layer that again allows one to focus on the business needs rather than the plumbing code to know what it takes to run it as AWS Lambda or Azure Function.
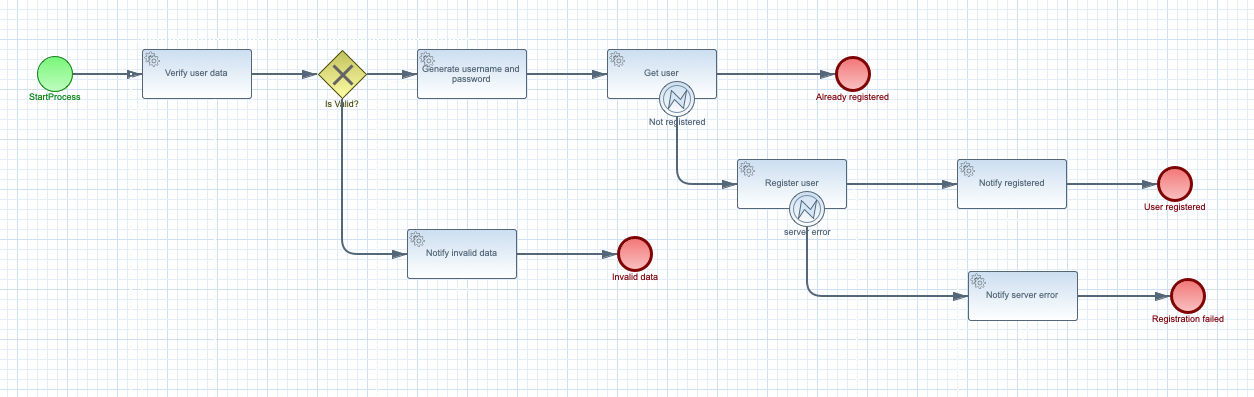
Above workflow, that is a user registration use case, clearly defines what is the business logic behind it and it is specific to a given domain. Workflow as a function means that it will be considered as a function, with well defined input and output. Deployment to the cloud function environment becomes the secondary aspect that is taken care of automatically.
Workflow as a function flow
Last but not least is the workflow as a function flow. It expands on the idea of workflow as a function where the main principle is to model business use case as complete as possible but break it down to number of functions that are
self contained - represent given piece of business logic
independent - are not aware of any other function
invokable at any time - can be triggered at any point in time regardless of the other functions
scalable - functions can be easily scaled to accommodate the traffic needs
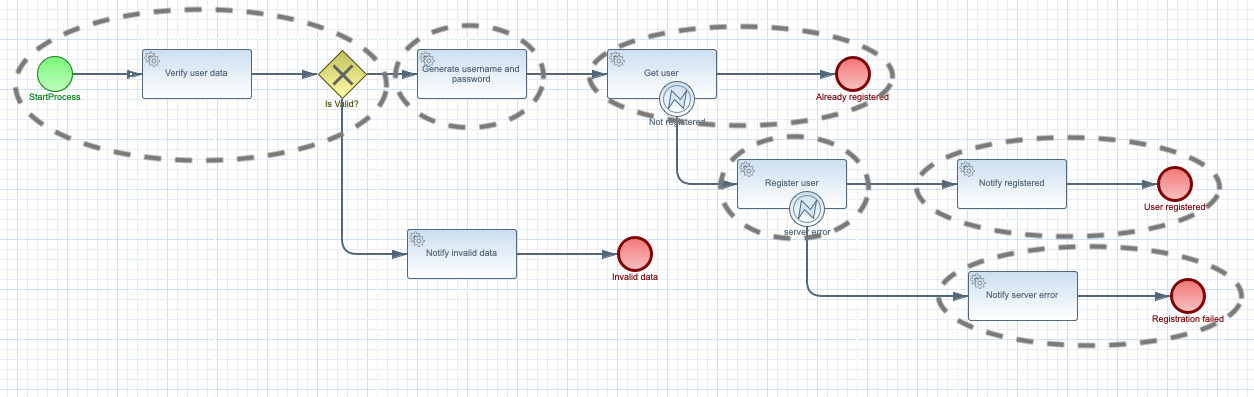
Business logic is then represented at runtime as individual functions that are triggered by events. Each function has input (an event) and can produce zero or many outputs (events). In turn, produced events can trigger other functions. What is important to mention is that functions do not trigger (or call) other functions explicitly, they simply produce events that other functions can consume.
This approach opens the doors for greater scalability as events can be efficiently distributed across many replicas of the functions.
Regardless of the concept used, workflows come with many features that make them useful to build core business logic. Something that is usually overlooked is the isolation characteristic that workflows bring by design. Workflows are built as a definition, sort of a blueprint and then this blueprint is instantiated to represent individual instances. Each instance exists in complete isolation, including its data, state, etc. Other features that are important are:
- reliable persistence,
- distributed timer/job scheduling and execution,
- messaging integration and many more.
Enough theory, can this actually run?
Being introduced to the concepts, an obvious question is - can it actually run? Is there anything that implements those concepts?
The short answer is YES!
This leads us to an open source framework called Automatiko that aims at building services and functions based on workflows. It implements all three concepts in a unique way. Let’s explore a little bit about the framework itself.
Automatiko is built with Java, it’s fully open source under Apache 2 license and can be freely used for any type of use cases. It is built on top of Quarkus, a cloud native Java toolkit for building services of any kind. Automatiko seamlessly integrates with Quarkus to allow developers to be effective and to have the best developer experience.
So how does Automatiko deliver workflow as a service, function and function flow?
First and foremost, it follow Quarkus philosophy to perform as many things at build time. So it does all the heavy lifting at build time. The main parts of this hard work is to transform the workflows into service, function or function flow. Let’s dive into each of the concepts' implementation to understand it better.
Workflow as a service in Automatiko
Automatiko at build time will look at workflow definitions and transform them to service interface - REST service interface with a complete definition based on OpenAPI. It can also create a GraphQL service interface that will open up for more advanced use cases to take advantage of applying principles of under and over fetching that GraphQL comes with.
As mentioned before, it integrates with Quarkus and allows users to use any feature of Quarkus to pair it with the need of workflows. Taking it even further Automatiko discovers what is available and binds to it without much of a hassle. An example of it is integration with data stores or messaging brokers that can be easily used from workflows.
A complete and ready to run example
Workflow as a function in Automatiko
To implement workflow as a function, Automatiko relies on Funqy, a Quarkus approach to building portable java functions. Similar to how it is done for workflow as a service, Automatiko at build time examines workflows and creates functions from them. As the aim for workflow as function is to be completely agnostic from the deployment platform, there is no need to change any line of code to make the function runnable on AWS Lambda, Azure Functions or Google Cloud Functions. It only requires project configuration (like dependencies) which Automatiko provides as configuration profiles.
A complete and ready to run example
Workflow as a function flow in Automatiko
Lastly, workflow as a function flow in Automatiko is also based on Funqy, but this time it leverages Knative project to build function chaining based on events (Cloud Events). Knative is a kubernetes based platform to deploy and manage modern serverless workloads. In particular, Knative eventing comes with universal subscription, delivery and management of events that allows to build modern applications by attaching business logic on top of the data stream - the events.
Again, at build time Automatiko breaks down the workflows into a set of functions and creates all the Knative manifest files required to deploy it. It comes with a trigger setup that binds all the pieces together (Knative eventing and the functions) so developers can easily move this from development to production.
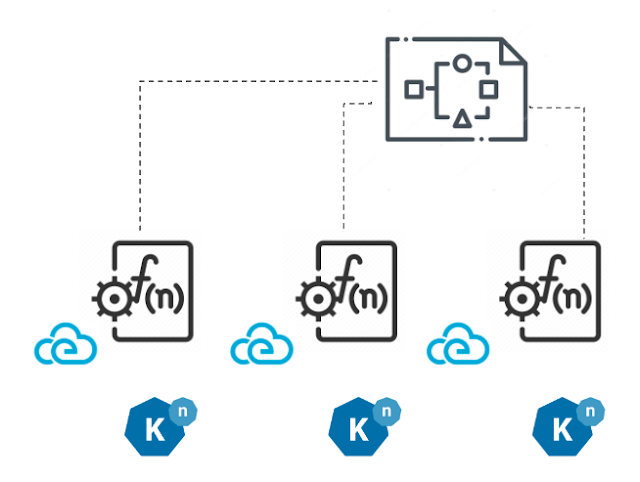
Note that Knative is a container based serverless platform. With that, Automatiko follows this approach and packages all functions into a single container image that can be scaled without problems. Knowing the characteristic of the functions - self-contained and invokable at any time, this container can be scaled to any number of replicas to provide maximum throughput as each replica has same runtime responsibility and can take execution based on incoming events.
A complete and ready to run example
A more complete article on workflow as a function flow is also available in Knative blog.
Wrapping up
This article was intended to put a slightly different light at workflows, especially in relation to the cloud. Main takeaway is to give readers a bit of food for thought that workflows are much more than service orchestration and that using them as part of the core business logic has a lot to offer. Concepts introduced and the implementation of them should be a good proof that workflows used to represent business logic is not just possible but as well efficient from development and maintenance stand point.

